The idea for CORELEX itself originates out of an NSF-ARPA funded research project on the CORE LEXICAL ENGINE, a joint research project of Brandeis University and Apple Computers Inc. [Pus95b]. Results of this research have been published in various theoretical and applied papers [Pus94b] [Joh95] [Pus96]. The research described in [Bui98], however, is the first comprehensive attempt to actually construct an ontology according to some of the ideas that arose out of this accumulated research and investigate its use in both classification and semantic tagging.
In CORELEX lexical items (currently only nouns) are assigned to systematic polysemous classes instead of being assigned a number of distinct senses. This assumption is fundamentally different from the design philosophies behind existing lexical semantic resources like WORDNET that do not account for any regularities between senses3.2. A systematic polysemous class corresponds to an underspecified semantic type that entails a number of related senses, or rather interpretations that are to be generated within context. The underspecified semantic types are represented as qualia structures along the lines of Generative Lexicon theory.
Acknowledging the systematic nature of polysemy allows one to:
Soon they all were removed to Central Laboratory School where their delicate transformation began.
Revise and complete wildlife habitat management and improvement plans for all administrative units, assuring proper coordination between wildlife habitat management and other resources.
Since WORDNET was not developed with an underlying methodology for distinguishing between different forms of ambiguity, often CORELEX classes may include lexical items that do not directly belong there. This requires further structuring using a set of theoretically informed heuristics involving corpus studies and lexical semantic analysis [Bui97].
Research undertaken within the Acquilex projects (Acquilex-I, Esprit BRA 3030, and Acquilex-II, Esprit Project 7315) mainly aimed at the development of methodologies and tools for the extraction and acquisition of lexical knowledge from both mono- and bi-lingual machine readable dictionaries (MRDs) of various European languages (Dutch, English, Italian and Spanish). Within Acquilex-II, a further source of information was taken into account to supplement the information acquired from dictionaries: substantial textual corpora were explored to acquire information on actual usage of words. The final goal of the research was the construction of a prototype integrated multilingual Lexical Knowledge Base for NLP applications, where information extracted from different kinds of sources and for different languages was merged.
Acquilex did not aim at developing broad coverage lexical resources. The focus was on establishing a common and theoretically sound background to a number of related areas of research. Hence, in the specific case of this project, it makes more sense to consider those information types which were extracted and/or formalised from different sources (see the following section) rather than giving detailed figures of encoded data.
Tools were constructed for recognising various kinds of semantic relations within the definition text. Starting from the genus part of the definition, hyponymy, synonymy and meronymy relations were automatically extracted and encoded within the mono-lingual LDBs. Also the differentia part of the definition was exploited, though to a lesser extent (i.e. only some verb and noun subclasses were considered), to extract a wide range of semantic attributes and relations characterising a word being defined with respect to the general semantic class it belongs to. Typical examples of relations of this class are: Made_of, Colour, Size, Shape and so forth; information on nouns Qualia Structure, e.g. Telic ([Bog90]; information on verb causativity/inchoativity; information on verb meaning components and lexical aspect; information on verb typical subjects/objects (cf. various Acquilex papers). Lexical information (such as collocations, selectional preferences, subcategorization patterns as well as near-synonyms and hyperonyms) was also extracted - although partially - from example sententes and semantic indicators (the latter used in bilingual dictionaries as constraints on the translation).
When considered in isolation, MRDs are useful but insufficient information sources for the construction of lexical resources, since it is often the case that knowledge derived from them can be unreliable and is in general asystematic. Hence, the use of corpora as additional sources of lexical information represented an important extension of the last phase of the project. Corpus analysis tools were developed with a view to (semi-)automatic acquisition of linguistic information: for instance, tools for part of speech tagging, or derivation of collocations or phrasal parsing. However, the real lexical acquisition task was not an accomplishment of this project which mainly focussed on the preparatory phase (i.e. development of tools).
In section §2.7, we gave examples of expanded TFS representations in which different levels of information (morpho-syntax, formal semantics and conceptual information)are correlated. Below is another example of an formalised lexical entry that is used as input by the LKB to generate an expanded TFS representation. The example corresponds to the Italian entry for acqua `water' (sense 1) which is defined in the Garzanti dictionary as liquido trasparente, incoloro, inodoro e insaporo, costituito di ossigeno e idrogeno, indispensabile alla vita animale e vegetale `transparent, colourless, odourless, and tasteless liquid, composed of oxygen and hydrogen, indispensable for animal and plant life':
acqua G_0_1
< sense-id : dictionary > = ("GARZANTI")
< sense-id : homonym-no > = ("0")
< sense-id : sense-no > = ("1")
< lex-noun-sign rqs > < liquido_G_0_1< lex-noun-sign rqs >
< rqs : appearance > = transparent
< rqs : qual : colour > = colourless
< rqs : qual : smell > = odourless
< rqs : qual : taste > = tasteless
< rqs : constituency : spec > = "madeof"
< rqs : constituency : constituents : first_pred > = "ossigeno"
< rqs : constituency : constituents : rqs_first_pred > <
ossigeno_G_0_0< lex-noun-sign rqs >
< rqs : constituency : constituents : rest_pred : first_pred > = "idrogeno"
< rqs : constituency : constituents : rest_pred : rqs_first_pred > <
idrogeno_G_0_0b< lex-noun-sign rqs >
< rqs : constituency : constituents : rest_pred : rest_pred > =
empty_list_of_preds_and_degrees.
Within the Acquilex LKB, lexical entries are defined as inheriting default information from other feature structures; those feature structures in their turn inherit from other feature structures. In lexical representation, default feature structures correspond to ``genus'' information; these feature structures are unified (through the default inheritance mechanism which is non-monotonic) with the non-default feature structure describing the information specific to the lexical entry being defined, which is contained in the ``differentia'' part of the definition. Hence, acqua inherits the properties defined for the lexical entry of liquido `liquid'. The general properties are then complemented with information which is specific to the entry being defined; in the case at hand, these features specify colour, smell and taste as well as constituency for ``acqua''. A fully expanded definition of the same lexical entry is obtained by combining its TFS definition (i.e. the one shown above) with the TFS definition of each of its supertypes.
Different TFS lexicon fragments, circumscribed to semantic classes of verbs and nouns (e.g. motion verbs or nouns denoting food and drinks), are available for different languages. The table below illustrates, for each language, the coverage of the final TFS lexicons which have been developed within the project:
| Dutch | English | Italian | Spanish | ||
| Noun Entries | Number of LKB Entries | ||||
| Food subset | 1190 | 594 | 702 | 143 | |
| Number of LKB Entries | |||||
| Drink subset | 261 | 202 | 147 | 254 | |
| Verb Entries | Number of LKB Entries | ||||
| Motion verbs subset | app. 360 | 303 | |||
| Number of LKB Entries | |||||
| Phsychological verbs subset | app. 200 | ||||
The fact that only part of the information extracted was converted into TFS form is also a consequence of the lack of flexibility of the class of TFS representation languages which causes difficulties in the mapping of natural language words - in particular word meanings which are ambiguous and fuzzy by their own nature - onto formal structures. In fact, the Acquilex experience showed the difficulty of constraining word meanings, with all their subtleties and complexities, within a rigorously defined organisation. Many meaning distinctions, which can be easily generalised over lexicographic definitions and automatically captured, must be blurred into unique features and values (see [Cal93]). On the other hand, the TFS formalism in the LKB has been used for developing models of lexical knowledge that go beyond the information stored in LDBs.
Unlike other work on the automatic analysis of machine readable dictionaries (see, for instance, the Acquilex projects) which focussed on semantic information which can be derived from the genus and differentia parts of the definition, in this project the acquisition work has mainly concentrated on syntagmatic links, namely the typical syntactic environment of words and the lexico-semantic preferences on their neighbours (whether arguments, modifiers or governors). In fact, due to the fact that Cobuild is a corpus-based dictionary and to particular structure of Cobuild definitions, this information type is systematically specified for all entries in the dictionary. However, also taxonomical information (i.e. hyperonymy, synonymy and meronymy relations) which could be extracted from the genus part of the definition was taken into account. Verb, noun and adjective entries were analysed and the extracted information was converted into a Typed Feature Structure Representation formalism following the HPSG theory of natural language syntax and semantics.
An example follows meant to illustrate the TFS representation format adopted within this project. The entry describes a transitive verb, accent (sense 4), which is defined in Cobuild as follows: ``If you accent a word or a musical note, you emphasize it''.
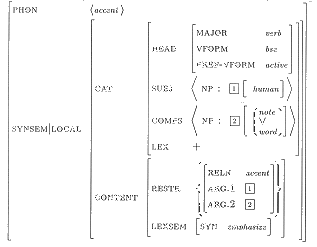
As can be noted, this structure complies, to a large extent, with the
general HPSG framework: it corresponds to the TFS associated with all
linguistic signs, where orthographic (``PHON''), syntactic and
semantic (``SYNSEM'') information is simultaneously represented. The
main differences lie in the insertion of Cobuild-specific features
such as ``DICTCOORD'' (encoding the coordinates locating a given entry
within a dictionary), ``LEXRULES'' (containing information about the
lexical rules relevant to the entry being defined), ``LEXSEM''
(carrying information extracted from the genus part of the definition)
and ``U-INDICES'' (i.e. usage indices, which characterize the word
being defined with respect to its contexts of use, specified through
the ``REGISTER'', the ``STYLE'' and the English variant (``DIAL-VAR'')
attributes). Other verb-specific attributes which have been inserted
to represent Cobuild information are ``PREF-VFORM'' and
``ACTION-TYPE'', the former intended to encode the preferential usage
of the verb being defined and the latter referring to the kind of
action expressed by the verb, e.g. possible, likely, inherent,
negative/unlikely, collective, subjective.
As in the case of Acquilex, also in this case the inadequacy of the formal machinery of a TFS representation language emerged, in particular with respect to the distinction between ``constraining'' and ``preferential information''. The distinction between constraints and preferences is not inherent in the nature of the data but rather relates to their use within NLP systems; e.g. the same grammatical specification (e.g. number or voice) can be seen and used either as a constraint or as a preference in different situations. Unfortunately, despite some proposals to deal with this typology of information, constraint-based formalisms as they are today do not appear suitable to capture this distinction (preferences are either ignored or treated as absolute constraints).
A sample of the TFS entries constructed on the basis of Cobuild information was then implemented in the Alep-0 formalism [Als91]. It emerged that, in its prototype version, this formalism presented several problems and limitations when used to encode lexical entries. The main objection was concerned with the expressivity of the formalism when dealing with lexical representations related to the inheritance between lexical entries. In fact, within the Alep framework inheritance between lexical entries is not supported, this mechanism being restricted to the system of types. But, when dealing with the representation of semantic information within the lexicon, the choice of exploiting the taxonomic chain to direct the inheritance of properties between lexical entries appears quite natural; this was possible for instance within the Acquilex Lexical Knowledge Base (see [Cop91b]). In this way, many of the advantages of encoding the lexicon as a TFS system are lost since, potentially, each lexical entry could be used as a superordinate from which information could be inherited.
The LRE-Delis project aimed at developing both a method for building
lexical descriptions from corpus material and tools supporting the
lexicon building method. The main goal of the project was developing a
method for making lexical description more verifiable and
reproducible, also through linking of syntactic and semantic layers.
The project aimed at the development and assessment of the working
method itself rather than the production of substantial amounts of
data. Only information related to a relatively small number of verbs
(plus a few nouns) was encoded. Lexical semantic descriptions of
lexical items falling within some semantic classes (perception verbs
and nouns, speech-act verbs, and motion verbs) were developed for
various languages (Danish, Dutch, English, French, and Italian) by
adopting the frame semantics approach (cf. [Fil92];
[Fil94]). Although a small set of lexical items was taken into
consideration, several hundreds of sentences containing them were
analysed and annotated in detail for each language (20+ types of
semantic, syntactic and morphosyntactic annotations). A Typed Feature
Structure dictionary was produced with entries for perception verbs of
EN, FR, IT, DK, NL, related to the corpora sentences. Reports on the
methodology followed, containing detailed discussion of the
syntax/semantics of the other verb classes treated, are also available
(e.g. [Hei95]).
Table 3.16 provides some numbers related to the kind of dataencoded:
|
The data encoded within Delis were acquired by manual work carried out on textual corpora. The methodology for corpus annotation, agreed on by all partners, is outlined in the CEES - Corpus Evidence Encoding Schema - ([Hei94]). This schema allows to:
Within DELIS, a list of aspects to be encoded for each verb and its surrounding context was agreed on for all the different linguistic layers:
As said above, many corpus sentences containing the words chosen were annotated. For perception verbs also TFS entries were produced. In the following an example of TFS is provided:
descry-att-tgt
[LEMMA: "descry"
FEG: < fe
[FE: exper-i
[INTENTION: +
SORT: human]
GF: subj
PT: np]
fe
[FE: p-target
[EXPECTED: +
SPECIFICITY: +
SALIENCE: -
DISTANCE: +
INTEREST: +]
GF: comp
PT: np] >
EVENT: vis-mod
[MODALITY: vis
DURATION: duration]].
The sense of the verb descry described in this FS involves an
intentional experiencer (indicated by characterising the verb as
'att' = attention) and a percept-target ('tgt'). The
attribute FEG ('Frame Element Group') has a list containing two frame
elements as its values: 'exper-i' and 'p-target'. Some semantic
features are encoded for each frame element, but also their
'grammatical function' and 'phrase-type'. Finally, also the 'event
properties' of the verb are indicated: in this case we have a 'visual'
MODALITY and a DURATION which is not further specified (although it
could also be given a 'short' or 'long' value).
The most interesting observation, derived from the data emerging from an analysis of the corpus, however, is that meaning distinction cannot always rely on the information taken from phrasal types, grammatical functions and their thematic roles. As is demonstrated by the data discussed in various reports (e.g. [Mon94]), idiosyncratic meanings can be enucleated by taking other information into account, usually missing in traditional paper dictionaries, at the level of morphosyntax, semantics, collocations, statistics and the interactions between different levels of information (cf. also [Cal96]).
In general we can state that the coverage in the experimental lexicons is much smaller than the other resources discussed here, but the richness and explictness of the data is much higher.
Corelex should be seen as the implementation of a particular theoretical approach to lexical semantics, capturing the dynamic properties of semantics. In this respect is it radically different from any of the other resources discussed here. Only in the case of EuroWordNet some of these ideas are being implemented in the form of the complex ILI-records (see §3.4.3). The underspecified types extracted in Corelex will be used as input in EuroWordNet (§ 3.4.3). The Acquilex multilingual LKB is a ``prototype'' database containing highly-structured and formalized data covering a well-defined set of syntactic/semantic classes of words. The semantic specific includes a QUALIA approach similar to Corelex, where meanings can also be derived by means of lexical rules. The language-specific lexical databases developed within the same project are on the one hand much richer in coverage, as traditional monolingual dictionaries, but are less formalized. As such they are closer to wordnets (§ 3.4). Furthermore, the English lexicons in Acquilex have been derived from the Longman dictionaries, showing that it is possible to derive complex lexicons from such resources.
The ET-10/Cobuild lexical database is constituted by a typology of entries of different parts of speech which were selected as representative of the different defining strategies adopted within the dictionary; this entails that the acquisition tools developed within the project should in principle be able to deal with the whole set of Cobuild entries. Hence, unlike other similar projects (such as Acquilex and Delis), here the set of formalised entries does not represent a semantically homogeneous dictionary subset but rather a typology of structurally different entries.
As said above, the data encoded within DELIS are only related to a small group of lexical items, chosen among words found in coherent semantic classes, and encoded just as an illustration of the working method followed. Thus the database itself, although rich of information on single verbs/nouns, does no longer appear as 'rich' when its coverage is considered, for instance when we compare it with resources such as EDR (§3.6) which contains quite similar semantic information for substantial portions of Japanese and English. Furthermore, within DELIS the focus of attention was mainly on the syntactic/semantic features of the different frame elements, whereas semantic relations such as those encoded in WordNet (§3.4.2) or EuroWordNet (§3.4.3) were not explicitly considered.
In the field of lexical semantics it is commonly assumed that important semantic properties of a lexical item are reflected in the relations it contracts in actual and potential linguistic contexts, namely on the syntagmatic and paradigmatic axes [Cru86]. Cobuild defining strategy takes into account both descriptive dimensions and accounts for both of them within the same definition structure. Hence, the ET-10/Cobuild lexicon contains information about synonymy, hyponymy and meronymy as well as about the typical syntactic-semantic environment of a given word.
The combination of syntactic and semantic information encoded in the DELIS database can be useful to address questions concerning the syntax-semantics interface. Furthermore, there is a strong relation between the characterization of predicate arguments in terms of frame elements and the traditional notion of thematic relations.
The main goal of the Acquilex project was the development and evaluation of different directions of research in related areas, ranging from automatic acquisition of lexical information from different sources and subsequent formalisation and multilingual linking in a LKB. Hence, its outcome mainly consists in the theoretical and methodological background for the creation of resources to be used within NLP applications.
The main goal of the ET-10 project was the development of a lexical acquisition strategy for the Cobuild dictionary and related tools. Hence, its outcome should be mainly considered from the methodological point of view. Yet, the acquisition tools developed within the project could in principle be usefully exploited to semi-automatically construct lexical resources for NLP applications.
Since the beginning, DELIS was conceived as a 'methodological' project whose purpose was to establish a theoretically motivated methodology for corpus-based computational lexicography and thus to prepare the ground for future development projects.


